This post will guide you to create a simple web application using Spring Boot and Apache Kafka.
Apache Kafka is a distributed streaming platform which is well known for moving data between systems in a distributed way.
Spring boot provides out of the box integration with Apache Kafka so that you don’t have to write a lot of boiler plate code to integrate Kafka in your web application.
Let’s get started!
Prerequisites
The only prerequisite is to have Kafka up and running in your environment. And to do that follow the links based on what operating system you’re using:
I generally prefer running all my system dependencies using docker which is an awesome tool for developers. Docker enables developers to focus on writing code and not worry about the system it will run on. If you want to run Kafka using docker, you can use the docker-compose.yaml file that I have added in the github repo. So before running the application just copy the file and perform a docker-compose up -d which will spin up a single Kafka broker, Zookeeper and will also create the required topic. This means you don’t need to perform step 6.
Steps to create Spring Boot + Apache Kafka web application:
Follow the below steps to create a Spring Boot application with which you can produce and consume messages from Kafka using a Rest client.
1) Creating the Web Application Template:
We’ll be using Spring Initializr to create the web application project structure and the easiest way to use Spring Initializr is to use its web interface.
1.1) Go to https://start.spring.io/:

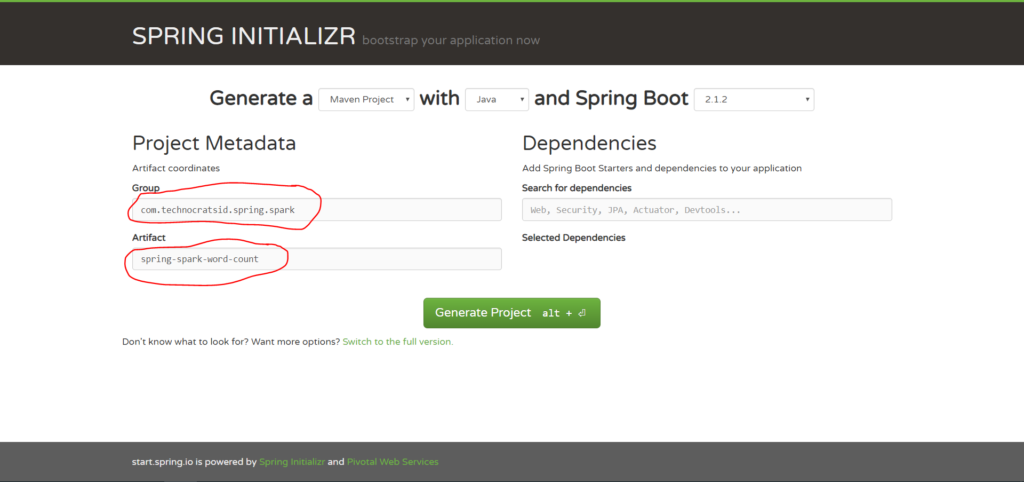
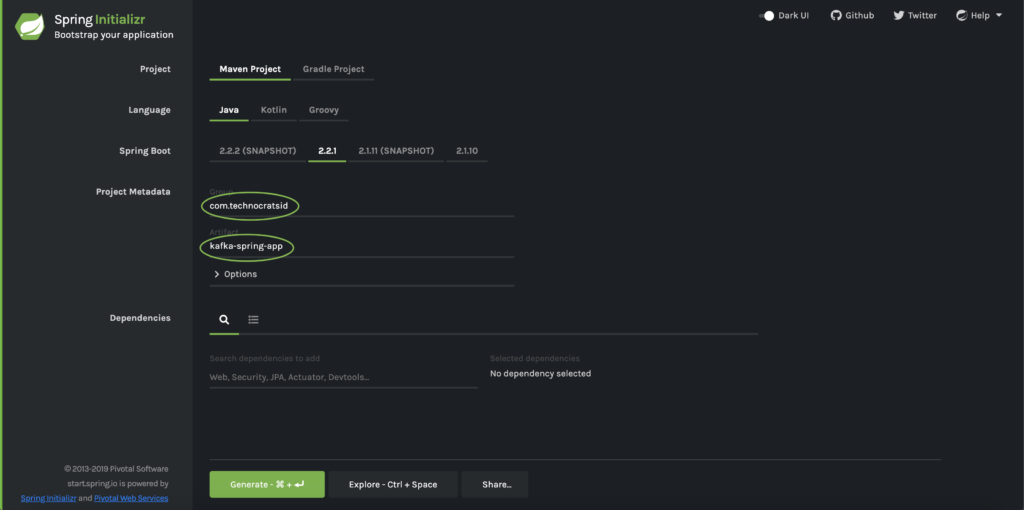
1.2) Enter Group and Artifact details:
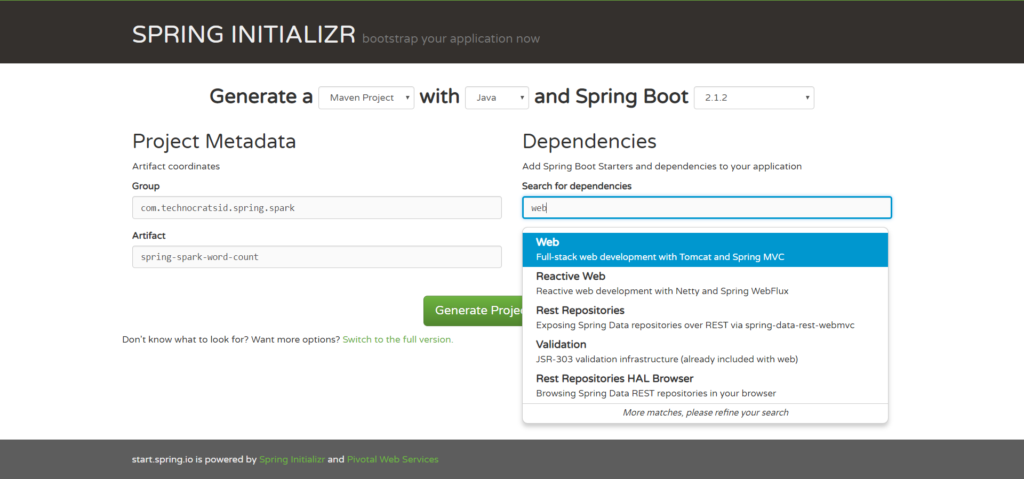
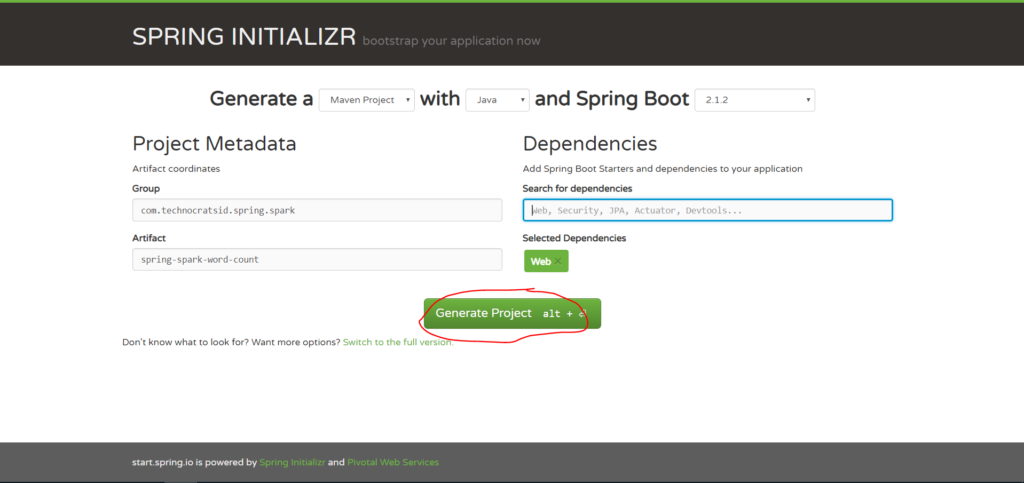
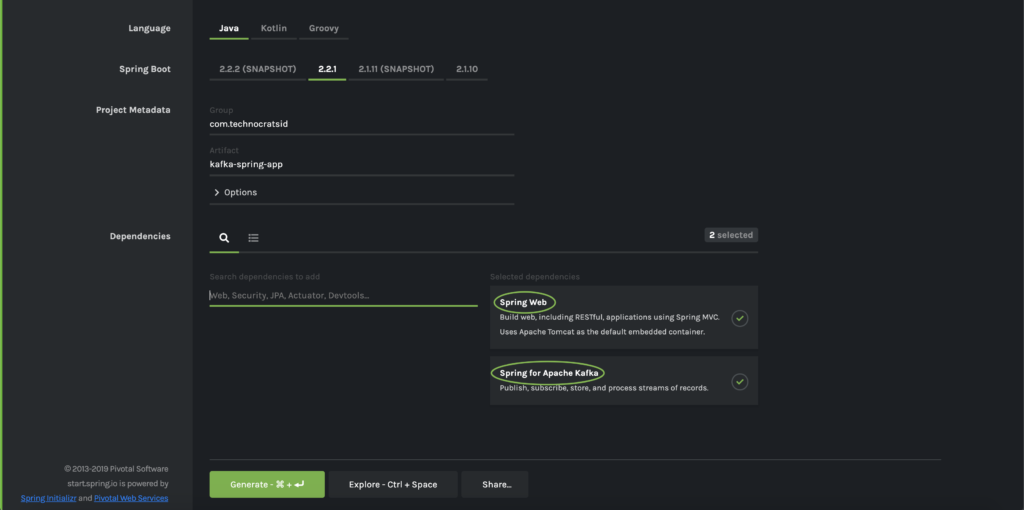
1.3) Add Spring Web & Spring for Apache Kafka dependencies:
Then, click on Generate Project.
This will generate and download the kafka-spring-app.zip file which is your maven project structure.
1.4) Unzip the file and then import it in your favourite IDE.
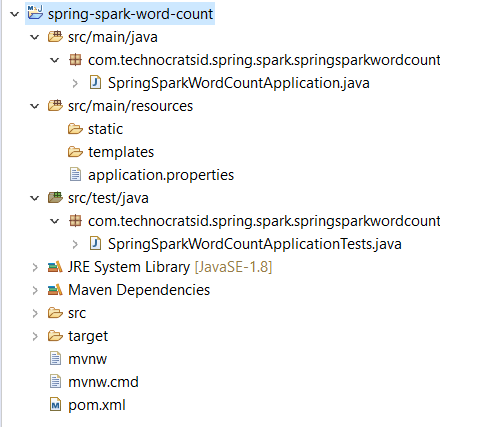
After importing the project in your IDE (Intellij in my case), you’ll see a project structure like this:

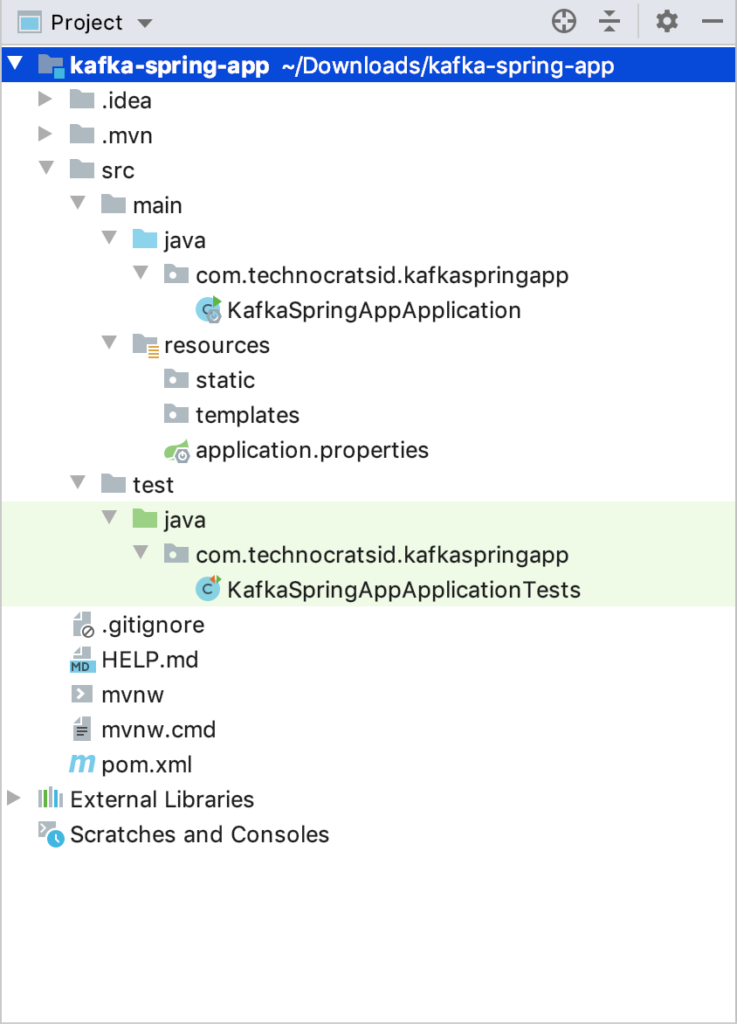
2) Configure Kafka Producer and Consumer:
We can configure the Kafka producer and consumer either by creating configuration classes (annotating classes with @Configuration annotation) for both producer and consumer or by using application.properties/application.yml file to configure them. In this tutorial, I’ll be demonstrating both for integrity. I personally prefer the latter approach (application.properties/application.yml) as it is quite handy and doesn’t require all the boilerplate code of the configuration class and that’s the beauty of spring boot one should leverage.
2.1) Creating configuration classes for Kafka consumer and producer:
Creating the consumer config class:
Create a class ConsumerConfig.java in package com.technocratsid.kafkaspringapp.config with the following content:
package com.technocratsid.kafkaspringapp.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
@EnableKafka
@Configuration
public class ConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServers;
@Value("${spring.kafka.groupId}")
private String groupId;
@Bean
public ConsumerFactory<String, String> getConsumer() {
Map<String, Object> configProp = new HashMap<>();
configProp.put(org.apache.kafka.clients.consumer.ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServers);
configProp.put(org.apache.kafka.clients.consumer.ConsumerConfig.GROUP_ID_CONFIG, groupId);
configProp.put(org.apache.kafka.clients.consumer.ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProp.put(org.apache.kafka.clients.consumer.ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(configProp);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(getConsumer());
return factory;
}
}
Note: Here we are declaring ConsumerFactory and ConcurrentKafkaListenerContainerFactory as beans (using @Bean annotation). This tells the spring container to manage them for us. ConsumerFactory is used to specify the strategy to create a Consumer instance(s) and ConcurrentKafkaListenerContainerFactory is used to create and configure containers for @KafkaListener annotated methods.
@Configuration is used to tell Spring that this is a Java-based configuration file and contains the bean definitions.
@EnableKafka annotation tells Spring that we want to talk to Kafka and allows Spring to detect the methods that are annotated with @KafkaListener.
@Value annotation is used to inject value from a properties file based on the property name.
The application.properties file for properties spring.kafka.bootstrap-servers and spring.kafka.groupId is inside src/main/resources and contains the following key value pairs:
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.groupId=kafka-spring-appIf you wish to run the application with a remote Kafka cluster then edit spring.kafka.bootstrap-servers pointing to your remote brokers.
Creating the producer config class:
Create another class ProducerConfig.java in the same package com.technocratsid.kafkaspringapp.config with the following content:
package com.technocratsid.kafkaspringapp.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
@Configuration
public class ProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServers;
@Bean
public ProducerFactory<String, String> getProducer() {
Map<String, Object> configProp = new HashMap<>();
configProp.put(org.apache.kafka.clients.producer.ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServers);
configProp.put(org.apache.kafka.clients.producer.ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProp.put(org.apache.kafka.clients.producer.ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProp);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(getProducer());
}
}
Note: Here we are declaring ProducerFactory and KafkaTemplate as beans where ProducerFactory is used to specify the strategy to create a Producer instance(s) and KafkaTemplate is a template for executing high-level operations like sending messages to a Kafka topic etc.
The value of kafkaServers is injected from the property spring.kafka.bootstrap-servers of the application.properties file same as ConsumerConfig class.
2.2) Configuring the Kafka consumer and producer using application.properties:
Open the application.properties file inside src/main/resources and add the following key value pairs:
spring.kafka.consumer.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=kafka-spring-app
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.producer.bootstrap-servers=localhost:9092
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
That’s it!
The above properties will configure the Kafka consumer and producer without having to write a single line of code and that’s the beauty of spring boot.
The key value pair in application.properties (allows to specify configuration) allows spring to do different things. With this file you can tell spring to configure things without writing any code.
3) Creating a consumer service:
Create a class KafkaConsumer.java in package com.technocratsid.kafkaspringapp.service with the following content:
package com.technocratsid.kafkaspringapp.service;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
@Service
public class KafkaConsumer {
public static List<String> messages = new ArrayList<>();
private final static String topic = "technocratsid-kafka-spring";
private final static String groupId = "kafka-spring-app";
@KafkaListener(topics = topic, groupId = groupId)
public void listen(String message) {
messages.add(message);
}
}
@KafkaListener allows a method to listen/subscribe to specified topics.
In our case whenever a message is produced on the topic “technocratsid-kafka-spring“, we are adding that message to a List of String (which is adding stuff to memory and it is not a good practice, in real world you might consider writing the messages to some datastore) so that we can display the messages later.
@Service tells Spring that this file performs a business service.
4) Creating a producer service:
Create a class KafkaProducer.java in package com.technocratsid.kafkaspringapp.service with the following content:
package com.technocratsid.kafkaspringapp.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Value("${app.topic}")
private String topic;
public void produce(String message) {
kafkaTemplate.send(topic, message);
}
}
Here we are using the KafkaTemplate send method to send messages to a particular topic.
@Autowired tells Spring to automatically wire or inject the value of variable from the beans which are managed by the the spring container. So in our case the value of kafkaTemplate is injected from the bean kafkaTemplate() defined in ProducerConfig class.
@Service tells Spring that this file performs a business service.
5) Creating a rest controller:
Create a class KafkaController.java in package com.technocratsid.kafkaspringapp.controller with the following content:
package com.technocratsid.kafkaspringapp.controller;
import com.technocratsid.kafkaspringapp.service.KafkaConsumer;
import com.technocratsid.kafkaspringapp.service.KafkaProducer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class KafkaController {
@Autowired
private KafkaConsumer consumer;
@Autowired
private KafkaProducer producer;
@RequestMapping(value="/send", method= RequestMethod.POST)
public void send(@RequestBody String data) {
producer.produce(data);
}
@RequestMapping(value="/receive", method=RequestMethod.GET)
public List<String> receive() {
return consumer.messages;
}
}
This class registers two endpoints /send and /receive which sends and receive messages to and from Kafka respectively, where /send is a POST request with String body and /receive returns the sent messages.
6) Create the required Kafka topic:
Before running the application create the following topic:
kafka-topics --bootstrap-server localhost:9092 --topic technocratsid-kafka-spring --create --partitions 1 --replication-factor 17) Running the web application:
Either run the KafkaSpringAppApplication class as a Java Application from your IDE or use the following command:
mvn spring-boot:run8) Testing the web app with a REST client:
To test the Spring Boot + Apache Kafka web application I am using Insomnia REST Client which is my favourite Rest client because of its simple interface. You can use any REST client.
Once your application is up and running, perform a POST request to the URL http://localhost:8080/send with the body {“key1”: “value1”}:

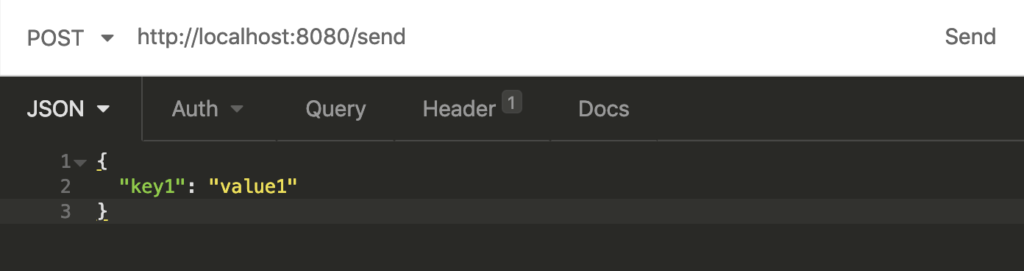
Then, perform a GET request to the URL http://localhost:8080/receive and this is the response you’ll get:

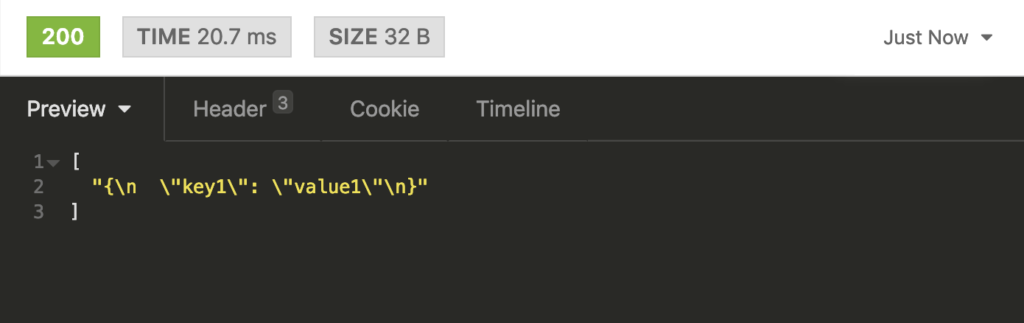
Congratulations on building a Spring Boot + Apache Kafka web application.
Hack into the github repo to see the complete code.