After thinking a lot about what to write next, I stumbled upon a very cool idea.
And this is what I thought I should do: Discover something interesting using code?
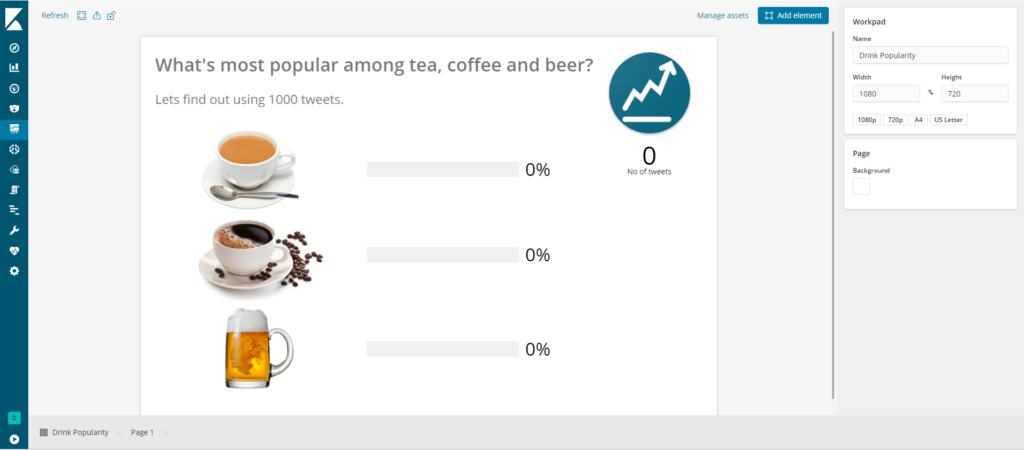
Let’s find out what’s the most popular drink among tea, coffee and beer in the world? All using code!!!
Yes, you heard it right.
How do we do this?
First and foremost, we need data!! And by data, I mean real time data because trends may change day to day. Social media is full of data, and we should thank Twitter for writing a Java HTTP client for streaming real-time Tweets using Twitter’s own Streaming API.
This client is known as Hosebird Client (hbc). Though it was written by Twitter a long time back and Twitter has deprecated some of its features but it will perfectly work for our requirement.
Also, we need to store the streaming data into some data-store and for this purpose we’ll be using Elasticsearch.
Why Elasticsearch?
The sole purpose of using Elasticsearch is to use Kibana’s Canvas to further visualise the data.
Canvas is a whole new way of making data look amazing. Canvas combines data with colours, shapes, text, and your own imagination to bring dynamic, multi-page, pixel-perfect, data displays to screens large and small.
Elastic
In simple words it is an application which lets you visualise data stored in Elasticsearch in a better and customised way in real time (while data is being ingested in Elasticsearch) and is currently in beta release.
You’ll be thrilled to see the end result using Elasticsearch Canvas.
Note: For the demonstration Elasticsearch & Kibana 6.5.2 are used.
Prerequisites:
Make sure Elasticsearch and Kibana are installed.
Let’s get started. Cheers to the beginning ?
Follow the steps below to implement the above concept:
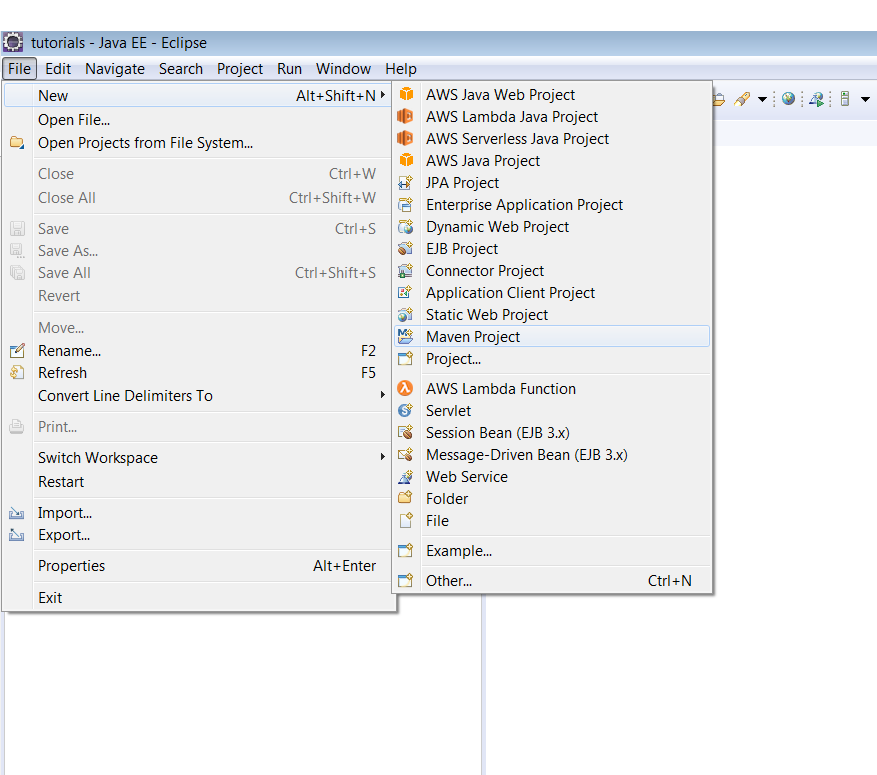
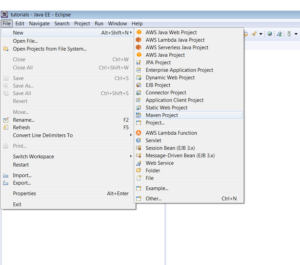
1) Setting up a maven project:
1.1) Create a Maven Project (for the demonstration I am using Eclipse IDE, you can use any IDE):
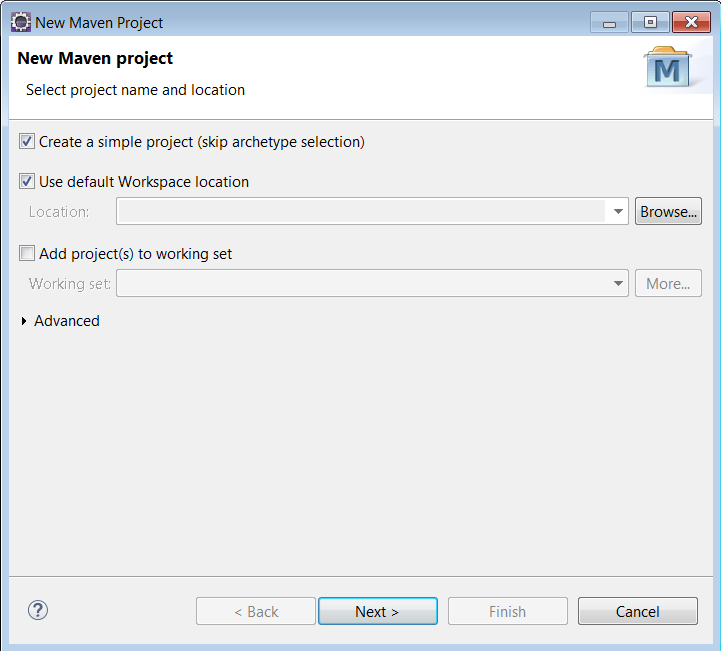
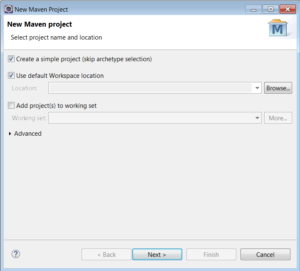
1.2) Skip the archetype selection:
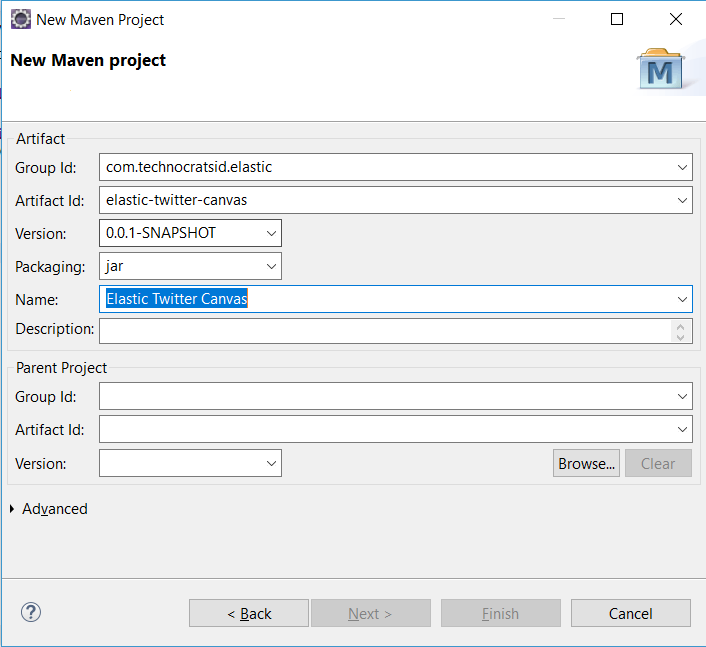
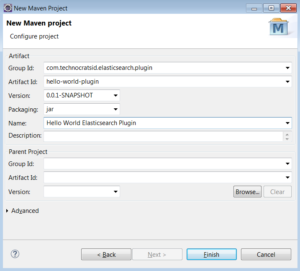
1.3) Add the Group Id, Artifact Id and Name, then click Finish:
2) Configuring the maven project:
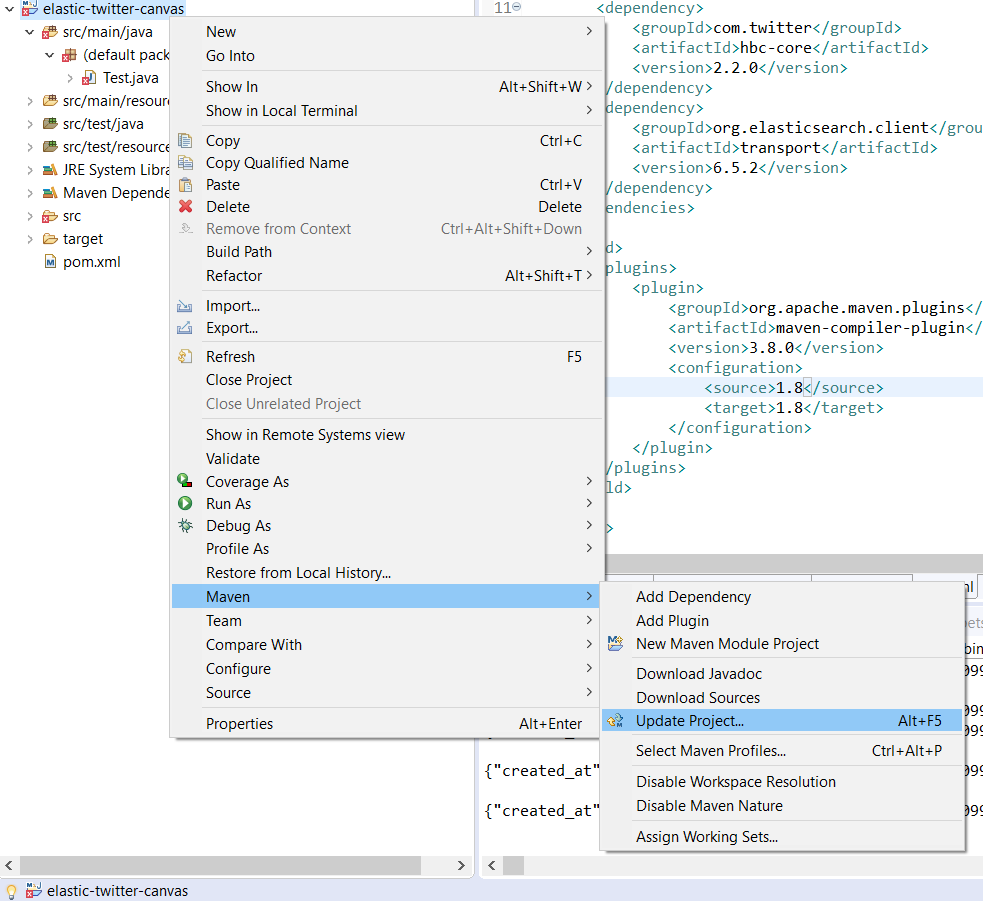
2.1) Open the pom.xml and add the following dependencies:
Alternately you can also press Alt+F5 after selecting the project.
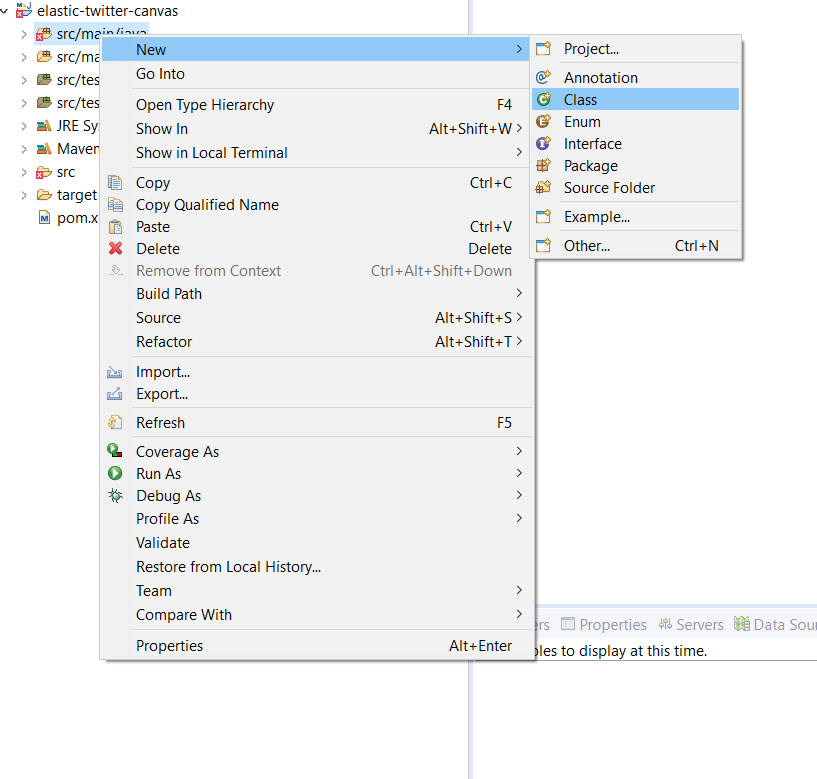
3) Create an Application class:
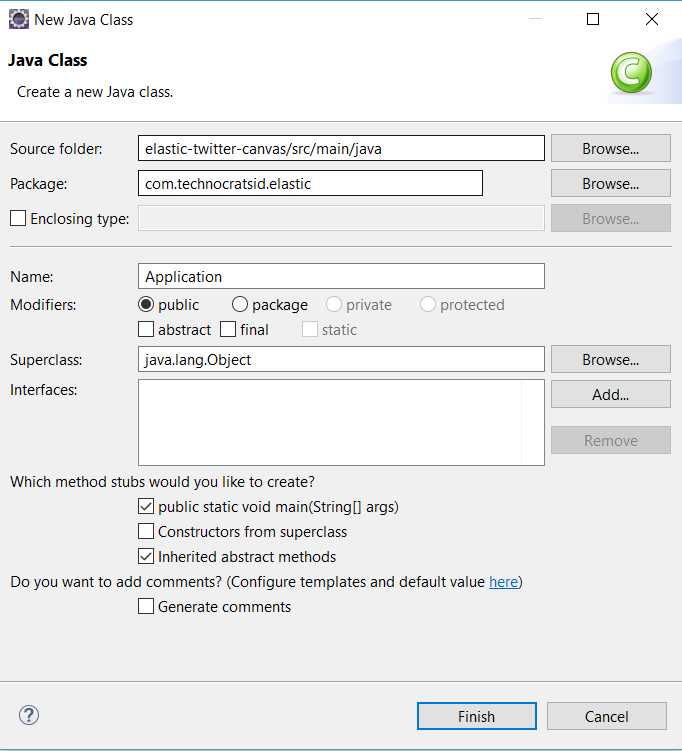
3.1) Go to src/main/java and create a new class:
3.2) Add the Package and Name of the class then click Finish:
4) Configure the Twitter Java Client:
4.1) Create a static method createTwitterClient in Application class and add the following lines of code:
public static Client createTwitterClient(BlockingQueue<String> msgQueue, List<String> terms) {
Hosts hosebirdHosts = new HttpHosts(Constants.STREAM_HOST);
StatusesFilterEndpoint hosebirdEndpoint = new StatusesFilterEndpoint();
hosebirdEndpoint.trackTerms(terms); // tweets with the specified terms
Authentication hosebirdAuth = new OAuth1(consumerKey, consumerSecret, token, secret);
ClientBuilder builder = new ClientBuilder().name("Twitter-Elastic-Client").hosts(hosebirdHosts)
.authentication(hosebirdAuth).endpoint(hosebirdEndpoint)
.processor(new StringDelimitedProcessor(msgQueue));
Client hosebirdClient = builder.build();
return hosebirdClient;
}
Notice, that this method expects two arguments: one is the BlockingQueue which is used as a message queue for the tweets and another is the List of terms we want our tweets to be filtered with (in our case “tea”, “coffee” & “beer”). So we are configuring our client to return real time filtered tweets (tweets with terms “tea”, “coffee” or “beer”).
Notice the line of code shown below:
Authentication hosebirdAuth = new OAuth1(consumerKey, consumerSecret, token, secret);
Twitter Java Client uses OAuth to provide authorised access to the Streaming API, which requires you to have the consumer/access keys and tokens. So to stream Twitter data you must have the consumer/access keys and tokens.
After getting the Consumer API key, Consumer API secret key, Access token and Access token secret,add them as Strings in the Application class:
private final static String consumerKey = "xxxxxxxxxxxxxxxxxx";
private final static String consumerSecret = "xxxxxxxxxxxxxxxxxx";
private final static String token = "xxxxxxxxxxxxxxxxxx";
private final static String secret = "xxxxxxxxxxxxxxxxxx";
It is not advisable to put this info in the program itself and should be read from a config file but for brevity I am putting these values in Application class as static final Strings.
5) Configure the Elasticsearch Transport Client:
5.1) Create a static method createElasticTransportClient in Application class and add the following lines of code:
public static TransportClient createElasticTransportClient() throws UnknownHostException {
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("localhost"), 9300));
return client;
}
The above method returns a Transport Client which talks to locally running Elasticsearch on port 9300.
If your Elasticsearch is running on some other port or host then you may need to change the values of “localhost” to your “host” and “9300” to your “port”, if your Elasticsearch cluster name is different that “elasticsearch”, then you need to create the client like this:
TransportClient client = new PreBuiltTransportClient(Settings.builder().put("cluster.name", "myClusterName").build())
.addTransportAddress(new TransportAddress(InetAddress.getByName("localhost"), 9300));
6) Streaming data from twitter:
Once the client establishes a connection:
// establish a connection
client.connect();
The blocking queue will now start being filled with messages. However we would like to read only first 1000 messages from the queue:
int count = 0;
while (!client.isDone() && count != 1000) {
String msg = msgQueue.take(); // reading a tweet
// Segregating the tweet and writing result to elasticsearch
count++;
}
7) Segregating tweets based on terms and then indexing the segregated result to Elasticsearch:
For brevity I am streaming first 1000 tweets (containing terms “tea”, “coffee” & “beer”), segregating them one by one and indexing the results in Elasticsearch.
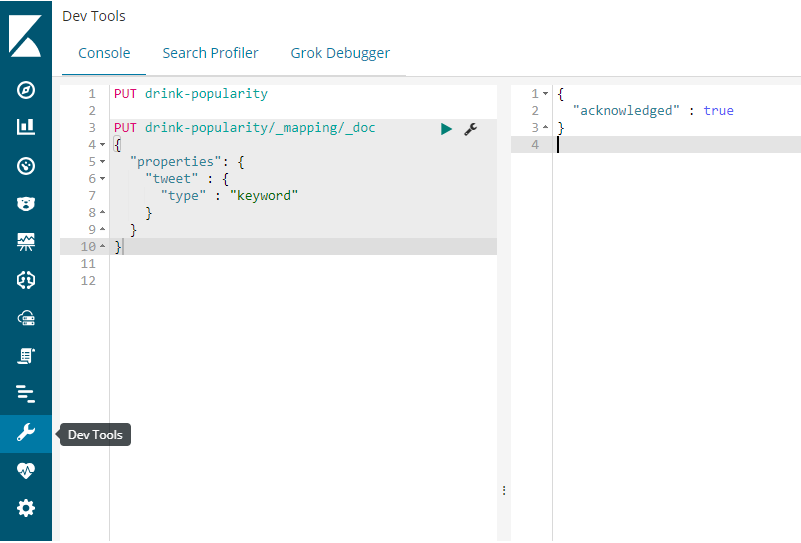
Example: Let’s say if a tweet contains the term “ tea ” then I will index the following document into Elasticsearch:
{ “tweet” : “tea” }
One thing I would like to clear: Let’s say if a tweet has tea and coffee both then I will consider only the first term. However, if you want to consider both the terms then hack into my repo stated at the end of this article.
This is how the complete Application class looks like:
The above request adds a new field tweet to the _doc mapping type.
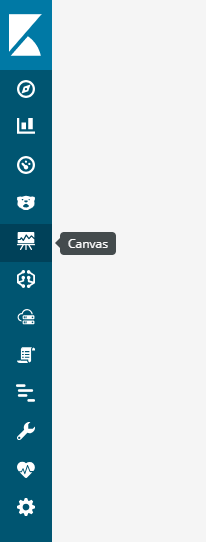
8.3) Go to Canvas:
8.4) I have already created a Canvas workpad. You just need to download it from here and import it in your own Canvas by clicking on Import workpad JSON file and then selecting the downloaded JSON file.
8.5) Once you have imported the workpad, open it by clicking on Drink Popularity workpad from Canvas workpads list.
This is what you should see:
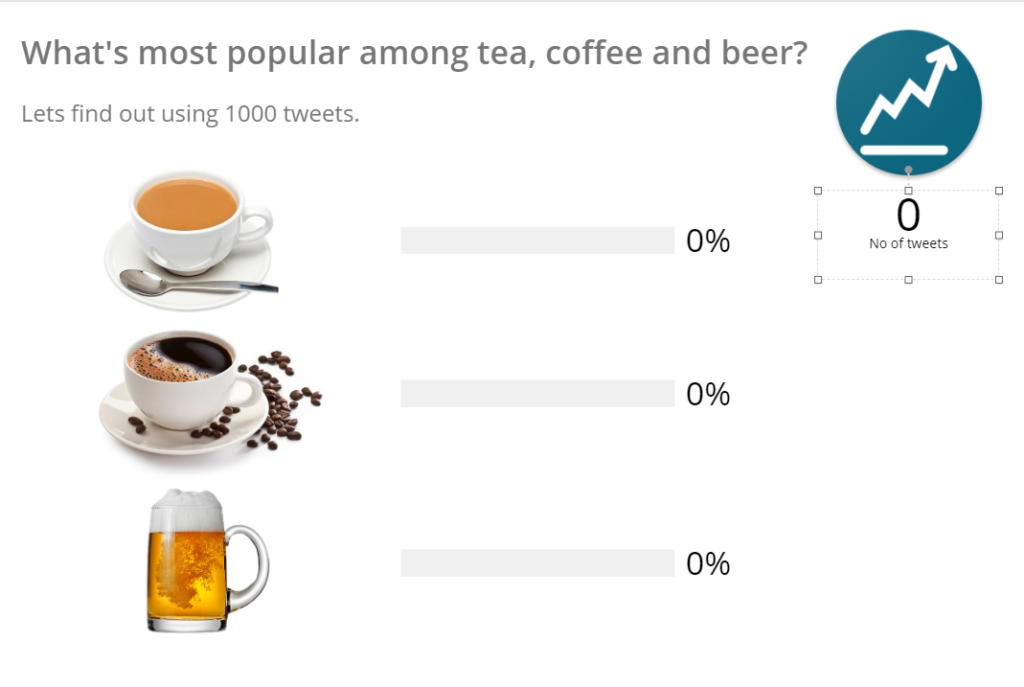
Now click on No of tweets metric:
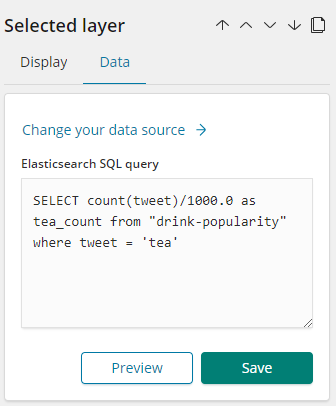
On the side panel of Selected Layer click on Data:
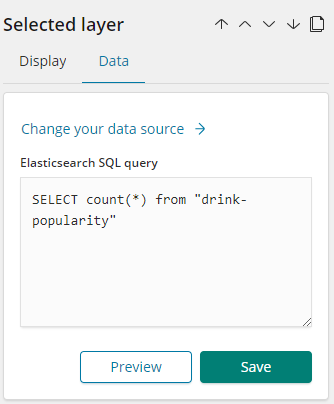
Notice the Elasticsearch SQL query used to fetch total no of tweets. Looks familiar right?
The above Elasticsearch SQL counts the total number of documents in drink-popularity index.
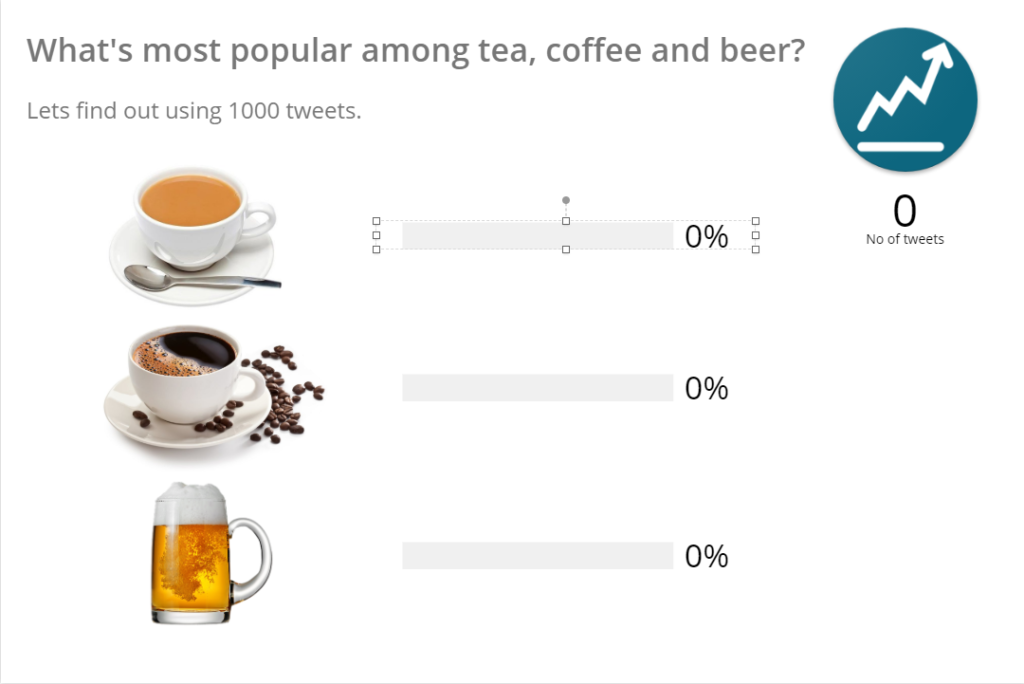
Do the same for one of the Horizontal progress bars:
Notice the Data panel:
So the above query is counting the no of tweets where tweet = ‘tea’ and dividing it by total no of tweets i.e. 1000.
Same thing has been done for other two progress bars.
9) Run the program to see live results in Canvas:
Before running the program the initial Canvas looks like this:
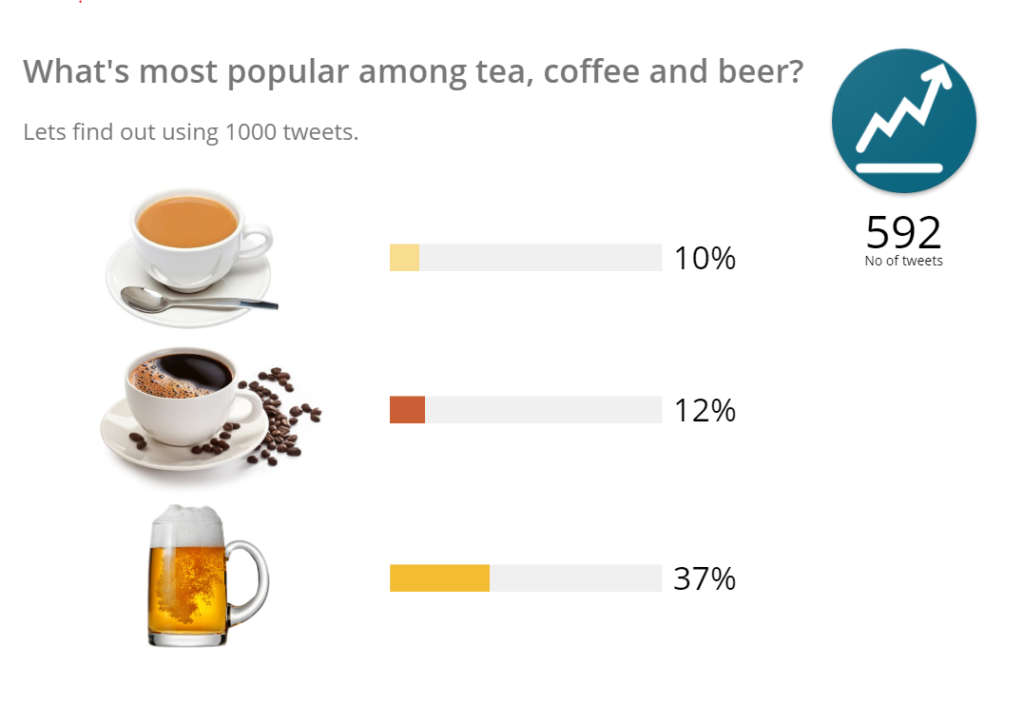
Now run the Application class and enable the auto-refresh in Canvas to see live updates and notice the Canvas.
After sometime:
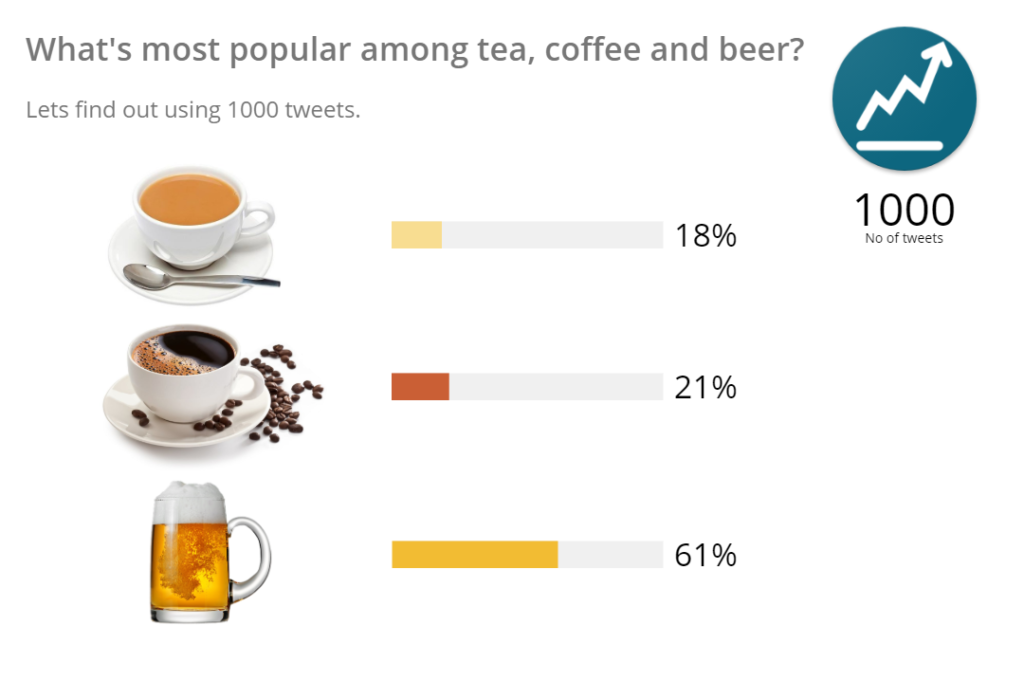
In the end:
Cheers !!! Beer is the winner 🙂 You can also check the results for a specific location by filtering the tweets based on location.
3) Then, click on Create an app (if you already have a Twitter App, then you can skip this step):
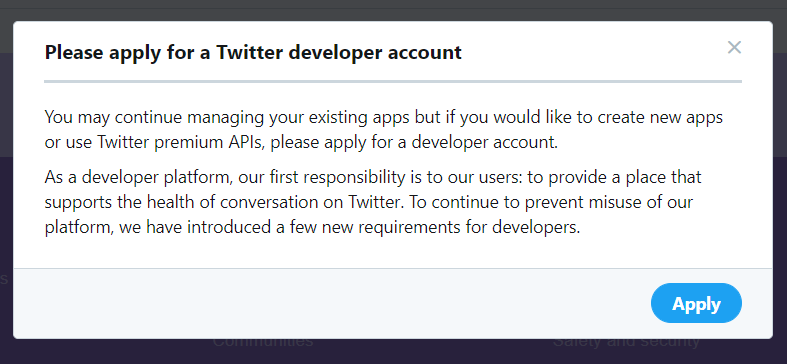
After clicking if you get a popup as shown below:
Then click on Apply as a Twitter Development account is mandatory to create new apps.
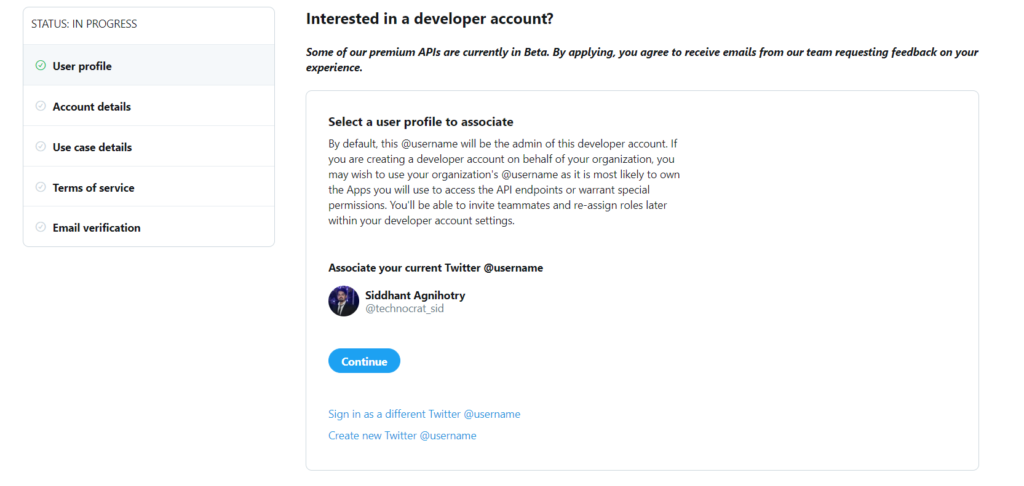
After that you’ll get a page as shown below:
Click on Continue.
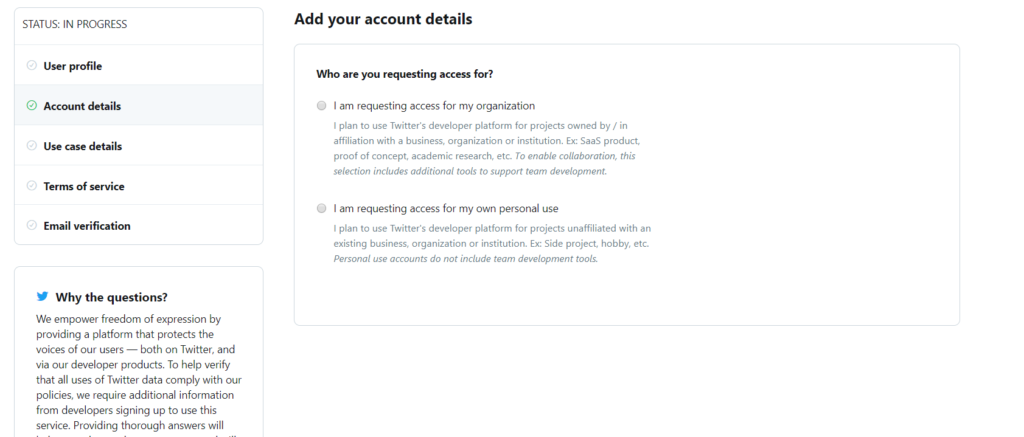
Now you’ll see a page as shown below:
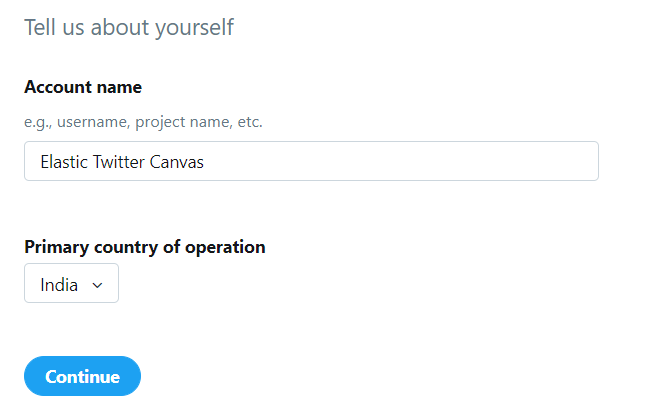
Select I am requesting access for my own personal use. After selecting this option, you’ll be asked to provide Account name and Primary country of operation
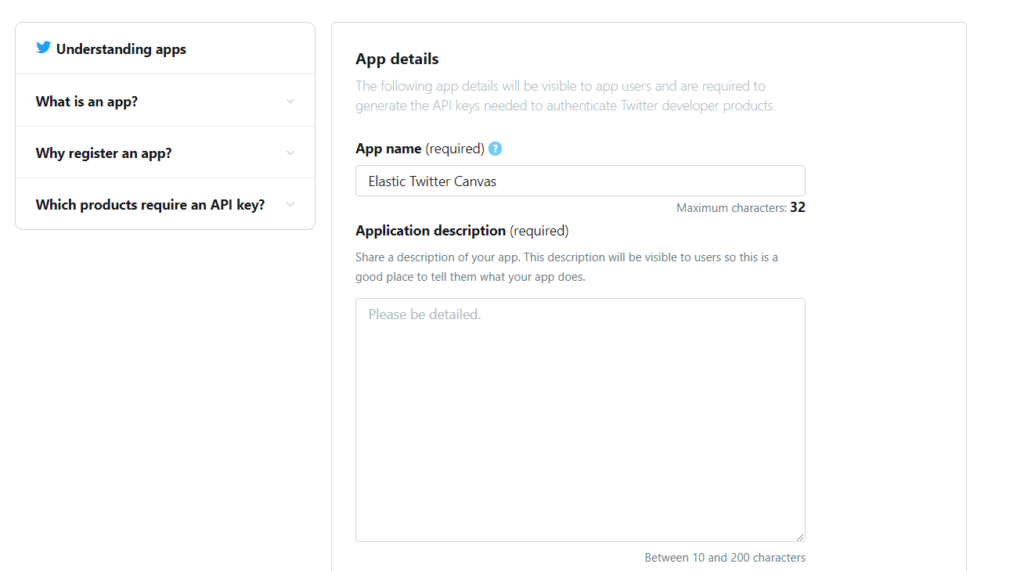
You can enter whatever you want but for the demonstration I am entering Elastic Twitter Canvas as Account name and India as Primary country of operation (see image below).
After that click on Continue.
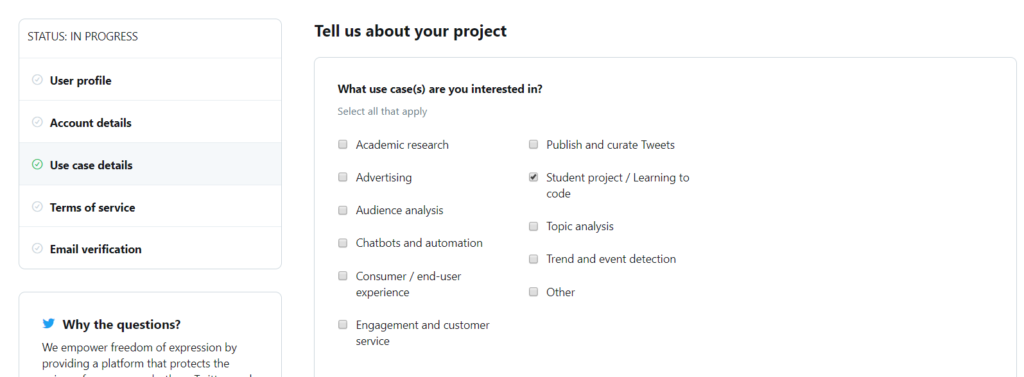
Now you’ll get a page shown in the below image. On the page, select Student project / Learning to code as your use case:
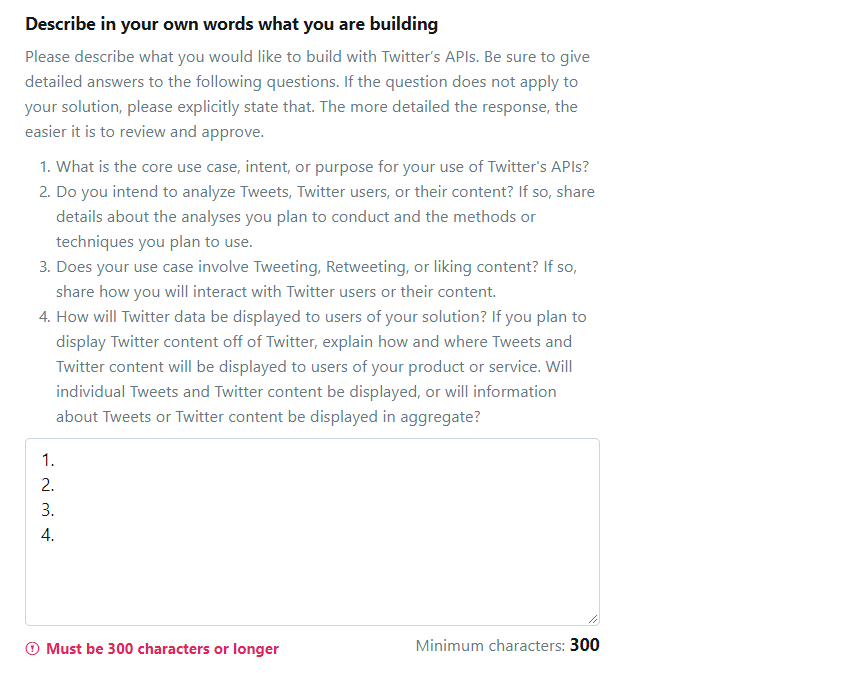
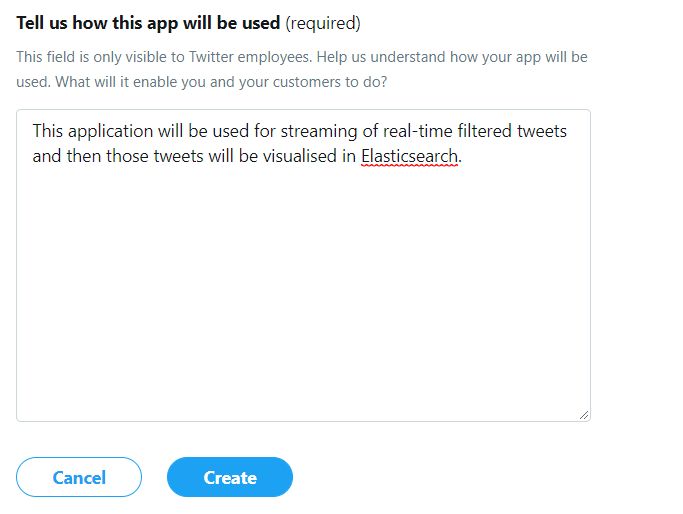
After that you’ve to describe few points about your project:
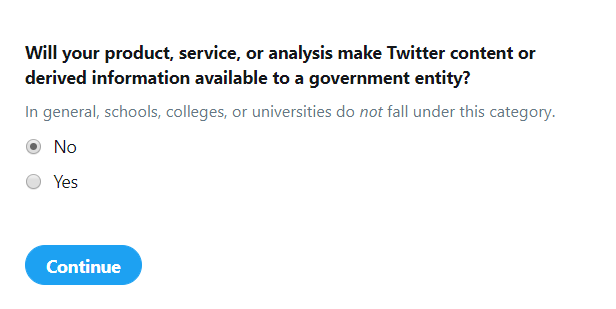
After writing at least 300 characters in the description box, select No for Will your product, service, or analysis make Twitter content or derived information available to a government entity? and then click on Continue:
In the next page accept the terms and conditions and click on Submit.
Once you click on Submit you’ll receive an email:
After that you need to verify your email and once the verification is done your Twitter Developer account will be ready.
Once your Twitter Developer Account is ready, click on Apps and then click on Create an app.
Provide an App Name & Description:
Enter a valid website name in the Website URL field. Since our app is for personal use, this isn’t really applicable. I have just entered a sample value. Please enter valid details if you wish to host your application.
Write the description:
Then click on Create.
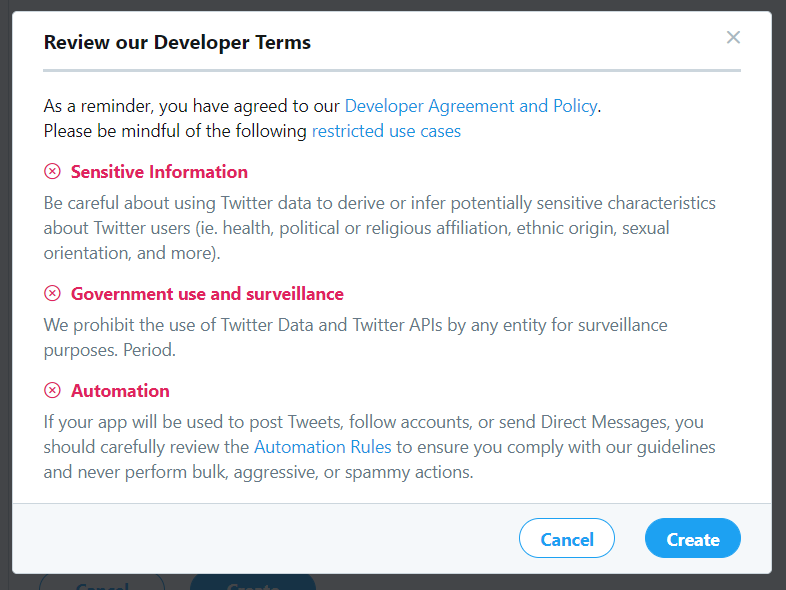
After that you’ll get a popup as shown below:
After reviewing the Developer terms, click on Create.
Bingo Your Twitter App is created!!
4) Getting the Keys and Tokens:
Click on Apps:
Click on Details:
After that go to Keys and Tokens:
These are my Customer API/Access keys and tokens. I have already changed the tokens and keys so you got no chance to access my data 😉
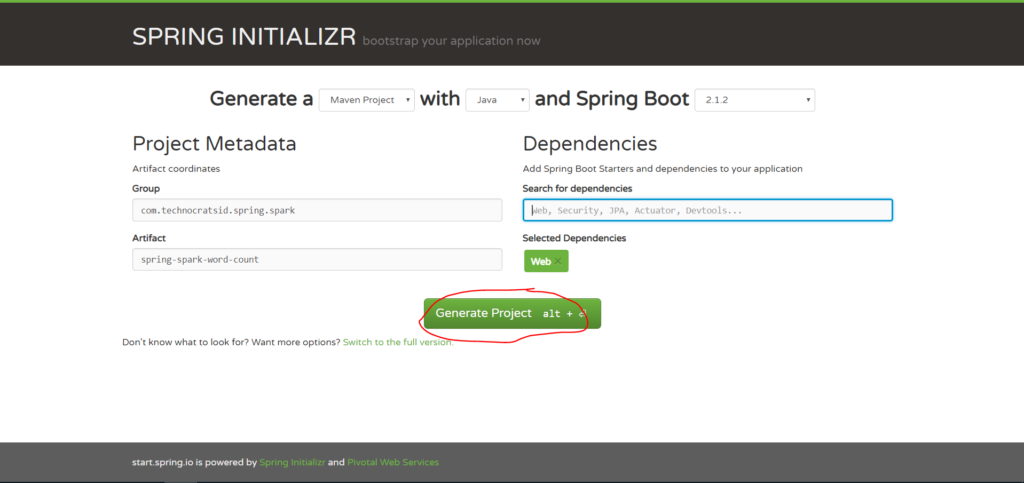
Note: By default, the project type is Maven Project and if you wish to select Gradle then just click on the Maven Project drop down and select Gradle Project.
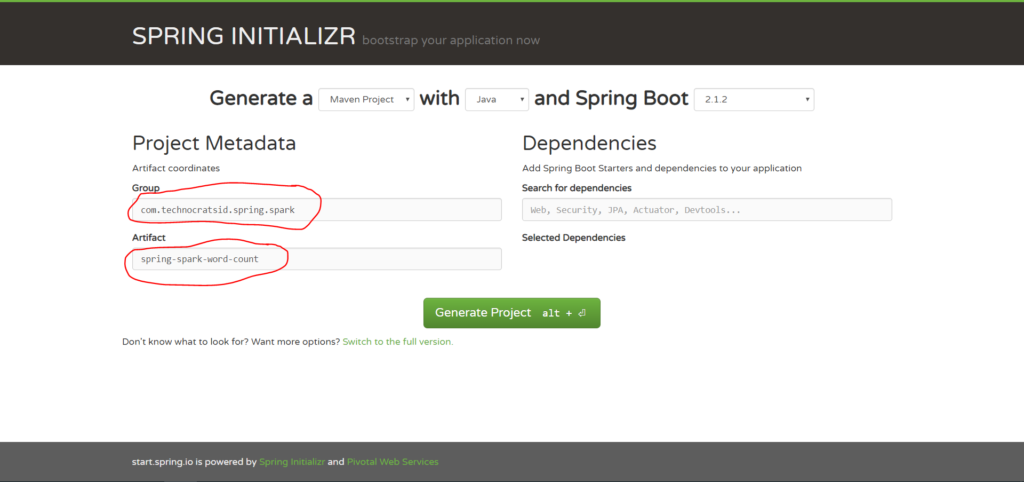
2. Enter Group and Artifact details:
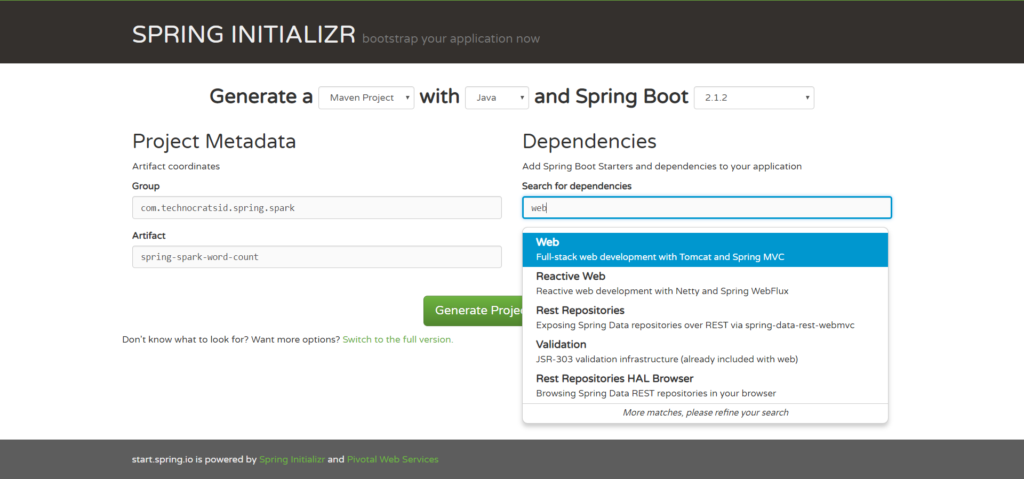
3. Type Web in Search for dependencies and select the Web option.
4. Now click on Generate Project:
This will generate and download the spring-spark-word-count.zip file which is your maven project structure.
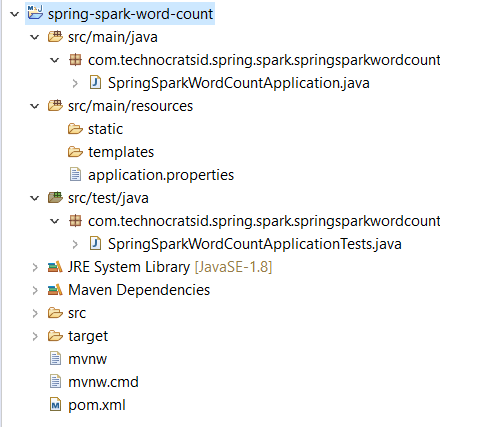
5. Unzip the file and then import it in your favourite IDE.
After you’ve imported the project in your IDE (in my case Eclipse) the project structure looks as follows:
The package names are automatically generated with the combination of group and artifact details.
Moving forward I’ve changed the package names from com.technocratsid.spring.spark.springsparkwordcount to com.technocratsid for brevity.
You can even do this while generating the project using Spring Initializr web interface. You just have to switch to full version and there you’ll find the option to change the package name.
2) Adding the required dependencies in pom.xml:
Add the following dependencies in your project’s pom.xml
Note: You might be thinking why we need to add the paranamer dependency as spark core dependency already has it? This is because JDK8 is compatible with paranamer version 2.8 or above and spark 2.4.0 uses paranamer version 2.7. So, if you won’t add the 2.8 version, you’ll get an error like this:
Request processing failed; nested exception is java.lang.ArrayIndexOutOfBoundsException: 10582
After this your complete pom.xml should look as follows:
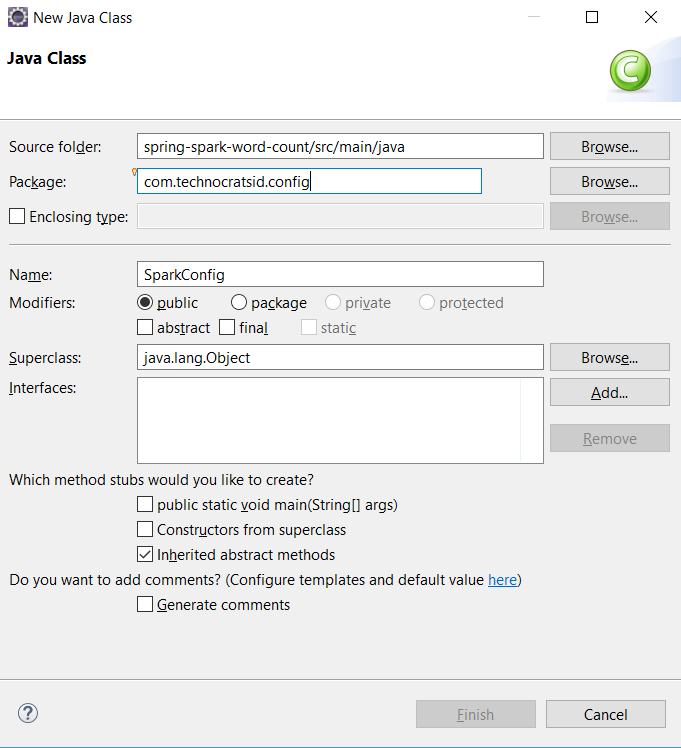
Create a class SparkConfig.java in package com.technocratsid.config.
Add the following content to SparkConfig.java:
@Configuration
public class SparkConfig {
@Value("${spark.app.name}")
private String appName;
@Value("${spark.master}")
private String masterUri;
@Bean
public SparkConf conf() {
return new SparkConf().setAppName(appName).setMaster(masterUri);
}
@Bean
public JavaSparkContext sc() {
return new JavaSparkContext(conf());
}
}
Import the packages.
Note: Here we are declaring the JavaSparkContext and SparkConf as beans (using @Bean annotation) this tell the spring container to manage them for us.
@Configuration is used to tell Spring that this is a Java-based configuration file and contains the bean definitions.
@Value annotation is used to inject value from a properties file based on the the property name.
The application.properties file for properties spark.app.name and spark.master is inside src/main/resources and looks like this:
spark.app.name=Spring Spark Word Count Application
spark.master=local[2]
local[2] indicates to run spark locally with 2 worker threads.
If you wish to run the application with your remote spark cluster then edit spark.master pointing to your remote cluster.
4) Creating a service for Word Count:
Create a class WordCountService.java in package com.technocratsid.service and add the following content:
@Service
public class WordCountService {
@Autowired
JavaSparkContext sc;
public Map<String, Long> getCount(List<String> wordList) {
JavaRDD<String> words = sc.parallelize(wordList);
Map<String, Long> wordCounts = words.countByValue();
return wordCounts;
}
}
Import the packages.
Note: This class holds our business logic which is converting the list of words into a JavaRDD and then counting them by value by calling countByValue() and returning the results.
@Service tells Spring that this file performs a business service.
@Autowired tells Spring to automatically wire or inject the value of variable from the beans which are managed by the the spring container.
5) Register a REST Controller with an endpoint:
Create a class WordCountController.java in package com.technocratsid.controller and add the following content:
Note: This class registers an endpoint /wordcount for a POST request with a mandatory query parameter words which is basically a string like (“abc|pqr|xyz”) and we are splitting the words on pipes (|) to generate a list of words and then using our business service’s count() method with the list of words to get the word count.
6) Run the application:
Either run the SpringSparkWordCountApplication class as a Java Application from your IDE or use the following command:
mvn spring-boot:run
7) Test your application from a REST client:
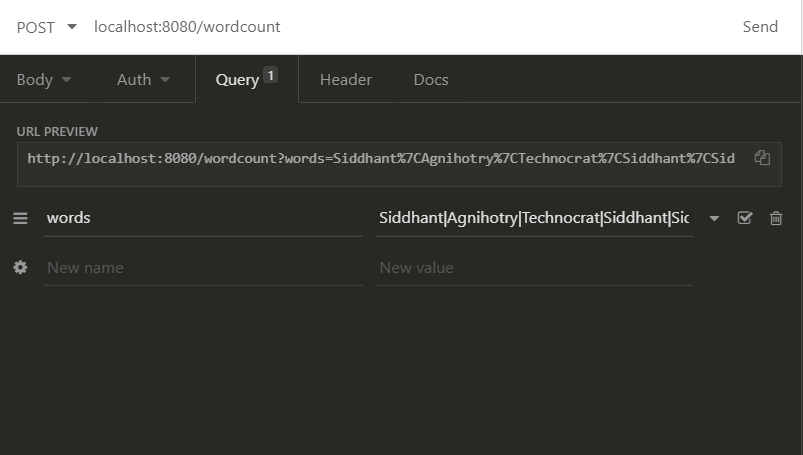
For this demo I am using Insomnia REST Client which is quite handy with simple interface. You can use any REST client you want like Postman and Paw etc.
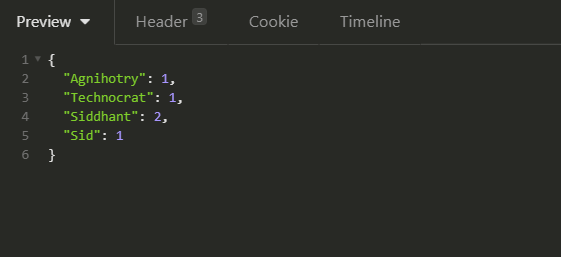
Once your application is up and running perform a POST request to the URL http://localhost:8080/wordcount with query parameter words=”Siddhant|Agnihotry|Technocrat|Siddhant|Sid”.
The response you’ll get:
You’ve just created your first Spring Boot Application and integrated Apache Spark with it.
If you want to hack into the code check out the github link.
Let’s say we have a text field “name” in an elasticsearch index with the following values: Siddhant,SIDTECHNOCRAT, and sid.
Now follow the conventions mentioned in String Sorting in Elasticsearch, which talks about using a text field that is not analyzed for sorting.
I am assuming that you’ve followed the conventions mentioned in the above link.
For the demo I am using Elasticsearch 6.4.1.
Let’s index the names:
PUT /my_index/_doc/1
{ "name": "Siddhant" }
PUT /my_index/_doc/2
{ "name": "SIDTECHNOCRAT" }
PUT /my_index/_doc/3
{ "name": "sid" }
Let’s sort the names:
GET /my_index/user/_search?sort=name.keyword
Output:
SIDTECHNOCRATSiddhantsid
Wait!! weren’t you expecting the result to be sid, Siddhant and SIDTECHNOCRAT.
You’re getting the results in the above order because the bytes used to represent capital letters have a lower ASCII value than the bytes used to represent lowercase letters, and as an international accepted standard, Elasticsearch follows ASCII sort order which is why the names are sorted with lowest bytes first.
In other words we’re getting results in lexicographical order which is perfectly fine for a machine but does not make much sense to human beings (expecting results to be sorted in alphabetical order).
If you want the results to be sorted in alphabetical order you should index each name in a way that ES should ignore the case while indexing.
To achieve this create a custom analyzer combining keyword tokenizer and lowercase token filter.
Then configure the text field you want to sort with the custom analyzer:
A plugin provides a way to extend or enhance the basic functionality of Elasticsearch without having to fork it from GitHub.
Elasticsearch supports a plugin framework which provides many custom plugin classes that we can extend to create our own custom plugin.
A plugin is just a Zip file containing one or more jar files with compiled code and resources. Once a plugin is packaged, it can be easily added to an Elasticsearch installation using a single command.
This post will explain how to create an Elasticsearch plugin for Elasticsearch 6.4.1 with maven and Eclipse IDE.
If you follow along you’ll be able to create a “Hello World!” plugin demonstrating the classic hello world example.
Cheers to the beginning 🙂
Steps to create an Elasticsearch plugin
1. Setting up the plugin structure:
1.1) Create a maven project using Eclipse IDE (you can use any IDE, I personally prefer Eclipse and IntelliJ).
1.2) Skip the archetype selection.
1.3) Add the Group Id, Artifact Id and Name, then click finish.
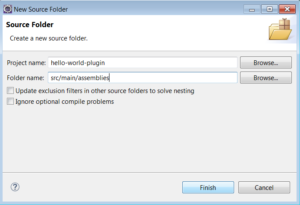
1.4) Create a source folder src/main/assemblies.
1.5) Click finish.
After this the plugin project structure should look like:
2.3) Add the plugin security policy file (Optional).
Some plugins require additional security permissions. A plugin can include an optional plugin-security.policy file containing grant statements for additional permissions..more
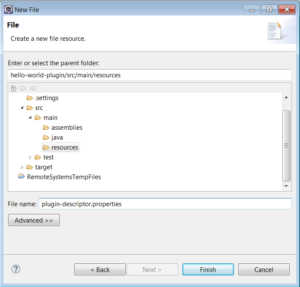
Create plugin-security.policy file in scr/main/resources.
and add the following content:
grant {
permission java.security.AllPermission;
};
The above content is just a reference and you might require different set of permissions. To know more about JDK permissions refer this.
After the creation of plugin-security.policy file, you have to write proper security code around the operations requiring elevated privileges.
Reason that we did not get the results in the above order:
As we haven’t specified index mapping beforehand, we are relying on default mapping. So in this case, the text field above will be analyzed with Standard Analyzer by default which mainly splits the text with spaces and removes stop words.
i.e. if we analyze “agnihotry siddhant”, it results in two terms “agnihotry” & “siddhant”.
which means when we index the text it is stored into tokens,
But we probably want to sort alphabetically on the first term, then on the second term, and so forth. In this case we should consider the text as whole instead of splitting it into tokens.
i.e. we should consider “technocrat sid”, “sid 01” and “agnihotry siddhant” as a whole which means we should not analyze the text field.
How do we not analyze a text field?
Before Elasticsearch 5.x
Before Elasticsearch 5.x text fields were stored as string. In order to consider a string field as a whole it should not be analyzed but we still need to perform a full text query on that same field.
So what we really want is to index the same field in two different ways, i.e. we want to sort and search on the same string field.
In Elasticsearch 5.x, the string type has been removed and there are now two new types: text, which should be used for full-text search, and keyword, which should be used for sort.
For instance, if you index the following document:
{
"name": "sid"
}
Then the following dynamic mappings will be created:
How you start Elasticsearch depends on how you installed it. I’ve installed Elasticsearch on Windows with a .zip package, in my case I can start Elasticsearch from the command line using the following command:
Type safety is prevention of typed errors in a programming language.
A type error occurs when someone attempts to perform an operation on a value that doesn’t support that operation.
In simple words, type safety makes sure that an operation o which is meant to be performed on a data type x cannot be performed on data type y which does not support operation o.
That is, the language will not allow you to to execute o(y).
Example:
Let’s consider JavaScript which is not type safe:
<!DOCTYPE html>
<html>
<body>
<script>
var number = 10; // numeric value
var string = "10"; // string value
var sum = number + string; // numeric + string
document.write(sum);
</script>
</body>
</html>
Output:
1010
The output is the concatenation of number and string.
Important point to note here is that JavaScript is allowing you to perform an arithmetic operation between an int and string.
As JavaScript is not type safe, you can add a numeric and string without restriction. This can lead to typed errors in type safe programming languages.
Let’s consider java which is type safe:
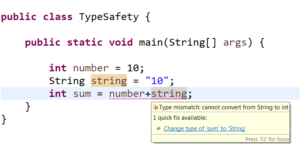
You can clearly observe that in java the compiler validates the types while compiling and throwing a compile time exception:
Type mismatch: cannot convert from String to int
As java is type safe, you cannot perform an arithmetic operation between an int and string.
Take away
Type-safe code won’t allow any invalid operation on an object and the operation’s validity depends on the type of the object.