Let’s say we have a text field “name” in an elasticsearch index with the following values: Siddhant,SIDTECHNOCRAT, and sid.
Now follow the conventions mentioned in String Sorting in Elasticsearch, which talks about using a text field that is not analyzed for sorting.
I am assuming that you’ve followed the conventions mentioned in the above link.
For the demo I am using Elasticsearch 6.4.1.
Let’s index the names:
PUT /my_index/_doc/1
{ "name": "Siddhant" }
PUT /my_index/_doc/2
{ "name": "SIDTECHNOCRAT" }
PUT /my_index/_doc/3
{ "name": "sid" }
Let’s sort the names:
GET /my_index/user/_search?sort=name.keyword
Output:
SIDTECHNOCRATSiddhantsid
Wait!! weren’t you expecting the result to be sid, Siddhant and SIDTECHNOCRAT.
You’re getting the results in the above order because the bytes used to represent capital letters have a lower ASCII value than the bytes used to represent lowercase letters, and as an international accepted standard, Elasticsearch follows ASCII sort order which is why the names are sorted with lowest bytes first.
In other words we’re getting results in lexicographical order which is perfectly fine for a machine but does not make much sense to human beings (expecting results to be sorted in alphabetical order).
If you want the results to be sorted in alphabetical order you should index each name in a way that ES should ignore the case while indexing.
To achieve this create a custom analyzer combining keyword tokenizer and lowercase token filter.
Then configure the text field you want to sort with the custom analyzer:
A plugin provides a way to extend or enhance the basic functionality of Elasticsearch without having to fork it from GitHub.
Elasticsearch supports a plugin framework which provides many custom plugin classes that we can extend to create our own custom plugin.
A plugin is just a Zip file containing one or more jar files with compiled code and resources. Once a plugin is packaged, it can be easily added to an Elasticsearch installation using a single command.
This post will explain how to create an Elasticsearch plugin for Elasticsearch 6.4.1 with maven and Eclipse IDE.
If you follow along you’ll be able to create a “Hello World!” plugin demonstrating the classic hello world example.
Cheers to the beginning 🙂
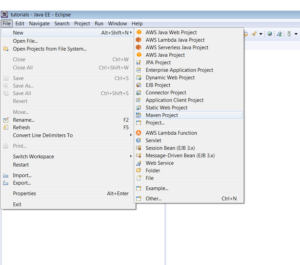
Steps to create an Elasticsearch plugin
1. Setting up the plugin structure:
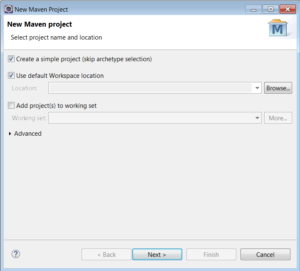
1.1) Create a maven project using Eclipse IDE (you can use any IDE, I personally prefer Eclipse and IntelliJ).
1.2) Skip the archetype selection.
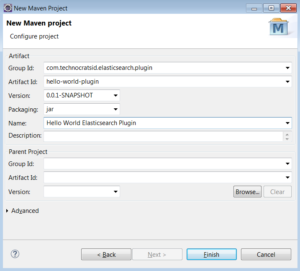
1.3) Add the Group Id, Artifact Id and Name, then click finish.
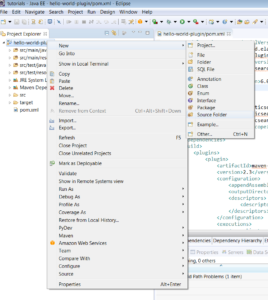
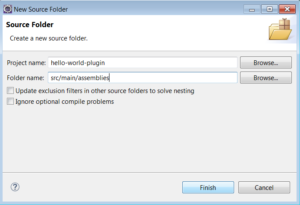
1.4) Create a source folder src/main/assemblies.
1.5) Click finish.
After this the plugin project structure should look like:
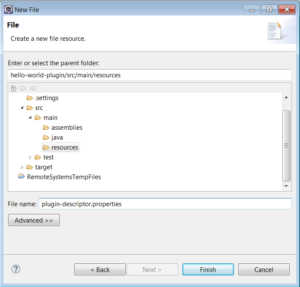
2.3) Add the plugin security policy file (Optional).
Some plugins require additional security permissions. A plugin can include an optional plugin-security.policy file containing grant statements for additional permissions..more
Create plugin-security.policy file in scr/main/resources.
and add the following content:
grant {
permission java.security.AllPermission;
};
The above content is just a reference and you might require different set of permissions. To know more about JDK permissions refer this.
After the creation of plugin-security.policy file, you have to write proper security code around the operations requiring elevated privileges.
Reason that we did not get the results in the above order:
As we haven’t specified index mapping beforehand, we are relying on default mapping. So in this case, the text field above will be analyzed with Standard Analyzer by default which mainly splits the text with spaces and removes stop words.
i.e. if we analyze “agnihotry siddhant”, it results in two terms “agnihotry” & “siddhant”.
which means when we index the text it is stored into tokens,
But we probably want to sort alphabetically on the first term, then on the second term, and so forth. In this case we should consider the text as whole instead of splitting it into tokens.
i.e. we should consider “technocrat sid”, “sid 01” and “agnihotry siddhant” as a whole which means we should not analyze the text field.
How do we not analyze a text field?
Before Elasticsearch 5.x
Before Elasticsearch 5.x text fields were stored as string. In order to consider a string field as a whole it should not be analyzed but we still need to perform a full text query on that same field.
So what we really want is to index the same field in two different ways, i.e. we want to sort and search on the same string field.
In Elasticsearch 5.x, the string type has been removed and there are now two new types: text, which should be used for full-text search, and keyword, which should be used for sort.
For instance, if you index the following document:
{
"name": "sid"
}
Then the following dynamic mappings will be created:
How you start Elasticsearch depends on how you installed it. I’ve installed Elasticsearch on Windows with a .zip package, in my case I can start Elasticsearch from the command line using the following command:
Type safety is prevention of typed errors in a programming language.
A type error occurs when someone attempts to perform an operation on a value that doesn’t support that operation.
In simple words, type safety makes sure that an operation o which is meant to be performed on a data type x cannot be performed on data type y which does not support operation o.
That is, the language will not allow you to to execute o(y).
Example:
Let’s consider JavaScript which is not type safe:
<!DOCTYPE html>
<html>
<body>
<script>
var number = 10; // numeric value
var string = "10"; // string value
var sum = number + string; // numeric + string
document.write(sum);
</script>
</body>
</html>
Output:
1010
The output is the concatenation of number and string.
Important point to note here is that JavaScript is allowing you to perform an arithmetic operation between an int and string.
As JavaScript is not type safe, you can add a numeric and string without restriction. This can lead to typed errors in type safe programming languages.
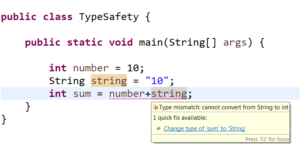
Let’s consider java which is type safe:
You can clearly observe that in java the compiler validates the types while compiling and throwing a compile time exception:
Type mismatch: cannot convert from String to int
As java is type safe, you cannot perform an arithmetic operation between an int and string.
Take away
Type-safe code won’t allow any invalid operation on an object and the operation’s validity depends on the type of the object.
An index alias is another name for an index or group of indices. It can substitute the original index name in any API.
Using index alias you can:
Create “views” on a subset of the documents in an index.
Group multiple indices under same name (This is helpful if you want to perform a single query on multiple indices at the same time).
Use Case
A possible use case is when your application has to switch from an old index to a new index with zero downtime.
Let’s say you want to re-index an index because of some reasons and you’re not using aliases with your index then you need to update your application to use the new index name.
How this is helpful?
Assume that your application is using the alias instead of an index name.
Let’s create an index:
PUT /myindex
Create its alias:
PUT /myindex/_alias/myalias
Now you’ve decided to reindex your index (maybe you want to change the existing mapping).
Once documents have been reindexed correctly, you can switch your alias to point to the new index.
Note: You need to remove the alias from the old index at the same time as we add it to the new index. You can do it using _aliases endpoint atomically.
Elasticsearch Analyzer is a wrapper which wraps three functions:
Character filter: Mainly used to strip off some unused characters or change some characters.
Tokenizer: Breaks a text into individual tokens(or words) based on certain factors like whitespace, ngram etc.
Token filter: It receives the individual tokens from tokenizer and then applies some filters on it (example changing uppercase terms to lowercase).
In a nutshell, an analyzer is used to tell elasticsearch how the text/phrase should be indexed and searched.
Why do we need analyzers?
Analyzers are generally used when you want to index a text or phrase. It is useful to break the text into words so that you can search on terms to get the document.
Example: Let’s say you have an index (my_index) with a field “intro” and you index a document:
Before Elasticsearch6.x, the analogy wrt Relational Databases was:
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns
Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
which led to incorrect assumptions.
SQL tables are independent of each other and if two tables have same column names then they will be stored separately and even they can have different definitions (eg: Table_1 & Table_2 have a common column name “date” which can have different meaning for both the tables), which is not the case in elastic mapping types. Internally, fields that have same names in different mapping types are stored as same Lucene field, having said that, it implies that both the fields should have the same mapping definition. This breaks the analogy mentioned above.
So in order to break this analogy ES6.x doesn’t allow more than one mapping type for an index. Even they are planning to remove _type in the upcoming versions.
Question: How you’re going to differentiate documents for the same index then?